
The great advances in Artificial Intelligence, in general, ChatGPT-like Large Language models (LLM), in particular, have led to a profusion of Generative Artificial Intelligence (GenAI) applications. They promise AI-empowered performance and efficiency improvements besides providing a natural language based easy-to-use interface. OpenAI based GPT-3 and GPT-4.x modules are generative pre-trained models that operate based on API model whereas Llama 2.x, Llama3.x, Mistral models are publicly available and can be downloaded. The co-lateral developments and advances in data availability, computing with LLM technologies made GenAI technologies more accessible and widely acceptable.
As GenAI solutions are integrated into Organizational applications, they bring into play both known and unexpected challenges. The organizations have to secure and monitor GenAI solutions. The advancements of GenAI are leveraged by adversaries to augment their attack strategies. The organizations have to employ appropriate preventive mechanisms to defuse or to avoid attacks. Further, they need continuous monitoring mechanisms to assess the Cyber hygiene and to take appropriate corrective actions.
An important issue with LLM’s security is that the control and data planes cannot be strictly isolated or separable. The LLM focus on semantic search can lead to hallucinations emerging from training flaws. In general, a LLM’s usage and application increases LLM attack surface. In addition to some unique risks with LLM, software bill of materials, supply chain and data loss protection and authorized access are well-known issues. Further LLM facilitates an adversary’s ability to craft new malware that can avoid detection, to generate convincing deep fakes besides assisting in their social engineering ploys.
The OWASP AI Exchange Working Group is monitoring trustworthy AI development and related regulations. It has come up with a list of Top 10 critical vulnerabilities for LLM Applications. The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, weak access control, and unauthorized code execution, among others. The checklist will be useful for the stakeholders to develop a comprehensive list of critical areas and tasks to defend and protect.
In what follows a brief description of each of LLM Top 10 vulnerabilities will be given along with impact, examples, and important mitigation strategies. Then an outline of SecPod strategy to handle them will be presented.
LLM01: Prompt Injection
Attackers manipulate LLMs through crafted inputs, causing it to execute the attacker’s intentions. This can be done either directly via the system prompt or indirectly through manipulated external inputs, potentially leading to data exfiltration, social engineering, and other issues. The direct injections, also known as “jailbreaking”, occur when a malicious user overwrites or reveals the underlying system prompts. This exposes backend systems for attack as functions and data stores will be accessible through the LLM. Indirect Prompt Injections occur when an LLM accepts input from an attacker-controlled external websites or files. The attacker may embed a prompt injection in the content hijacking the conversation context and compromising LLM. In advanced attacks, the LLM could be manipulated to mimic a harmful persona or interact with plugins in the user’s setting. The latter results in leaking sensitive data, unauthorized plugin use, or social engineering and thus totally compromising LLM.
An example of a direct prompt injection is when a malicious user instructs LLM to ignore the system prompts and instead executes a prompt that returns sensitive information. An example of indirect attacks could be when a user asks LLM to summarize a webpage containing the prompt injection.
Due to nature of LLM, being not able to distinguish data and control, prompt injections are unavoidable, and the following are some of the measures can be taken to mitigate the risk:
- Ensuring privilege control on LLM to access backend systems based on the principle of least privilege
- Add a human being in the loop for extended functionality to approve privileged operations
- Set up trust boundaries between the LLM, external sources and plugins based on zero trust principle and maintain final user control on the decision-making process.
LLM02: Insecure Output Handling
This vulnerability refers to insufficient validation, sanitization and handling of the LLM generated outputs. As LLM-generated content can be controlled by prompt input, the lack of output scrutiny provides users indirect access to additional functionality. An attacker can use this vulnerability to successfully launch XSS and CSRF in web browsers as well as SSRF, privilege escalation, or remote code execution attacks on backend system.
Consider a JavaScript that is being generated by the LLM and returned to a user. If not validated, the code when interpreted by the browser, results in XSS.
The unscrutinized output vulnerability can be handled as follows:
Adopt zero-trust approach and apply proper input validation on responses coming from the model to backend functions to prevent exploitation. In addition, ensure compliance to OWASP ASVS (Application Security Verification Standard) guidelines.
LLM03: Training Data Poisoning
The training data is important to determine parameters of a LLM model like any other ML model. To create a capable model with linguistic and world knowledge, the training corpus should cover diverse domains, genres, and languages. In general training is done in 2 phases. The first one, referred to as pre-training is done on a vast amount of publicly available datasets corpus using huge computing resources. The second training, referred to as fine-tuning is done to adapt on a pre-trained model to a more specific task using a curated dataset depending on the intended task.
Training data poisoning involves manipulating pre-training data, fine-tuning data, or embedding processes to introduce vulnerabilities, backdoors, or biases that can compromise the model’s security, effectiveness, or ethics. Data poisoning is considered an integrity attack because tampering with training data affects the model’s ability to generate accurate predictions. Further, poisoned data may lead to risks like degraded performance, security exploits, or reputational damage, even if users distrust the problematic AI output. If any external data sources are used, they pose a higher risk, as model creators cannot ensure the content’s accuracy or bias-free nature.
A typical example of data poisoning is when an unsuspecting user is indirectly injecting sensitive or proprietary data into the training processes of a model which is returned in subsequent outputs. Another example of data poisoning happens when a model is trained using data which has not been vetted by its source, origin or content in any of the training stage examples which can lead to erroneous results if the data is tainted or incorrect.
The vulnerability can be mitigated as follows:
- Supply Chain Verification of External datasets – This ensures that the intended dataset is used for training and tuning.
- Maintain “ML BOM” records – Ensures that libraries are correctly installed based on model card.
- Data Legitimacy Verification
- Include adversarial robustness to the training lifecycle with the auto poisoning technique.
LLM04: Model Denial of Service
This vulnerability occurs when an attacker interacts with an LLM in a way that consumes an exceptionally heavy amount of resources. This can result in a decline in the quality of service for them and other users, as well as potentially incurring high resource costs. A related major security concern is the possibility of an attacker interfering with or manipulating the context window of an LLM. Another worrying factor is a general unawareness among developers regarding this vulnerability.
A typical example of this vulnerability is sending unusually resource-consuming queries that use unusual orthography or sequences. Or an attacker sends a stream of input or repetitive long inputs to the LLM that exceeds its context window, causing the model to consume excessive computational resources.
Techniques to mitigate denial of service include the following: –
- Input Validation and Content filtering – This ensures adherence to defined limits and filters out any malicious content.
- Resource Caps – Prioritizes simple resource requests and slows down complex requests. Implement queue systems to limit the number of queue actions total actions in a system reacting to LLM responses.
- API Rate Limits – Restricts the number of requests that can be made within a specific timeframe
- Continuously monitor the resource utilization of LLM to identify abnormal spikes or patterns that may indicate a DoS attack.
- Promote awareness about potential DoS vulnerabilities in LLMs and provide guidelines for secure LLM implementation.
LLM05: Supply Chain Vulnerabilities
Any vulnerability in the supply chain of LLMs can impact the entire life cycle of LLM training to deployment. This affects the integrity of training data and ML models. The deployments based on these vulnerabilities can lead to biased outcomes, security breaches, or even complete system failures. In addition, LLM Plugin extensions can bring their own vulnerabilities and can lead to data exfiltration and other issues.
Such vulnerabilities can stem from outdated software, susceptible pre-trained models, poisoned training data, and insecure plugin designs.
Here are some ways to mitigate supply chain vulnerability: –
- Supplier Evaluation – Meticulously vet data sources and suppliers; Check their security audit reports, privacy policies and trusted suppliers; check for alignment of model operator policy with your data protection policies; get assurances and legal mitigations against using copyrighted material from model maintainers
- Third-party Plugin Testing – Use reputed brands and ensure they are tested for application requirements. Test against LLM-aspects of Plugin to mitigate
- OWASP A06 mitigation of outdated component – Understand and apply the mitigations found in the corresponding OWASP document.
- Maintain an up-to-date inventory – Use signed SBOM to detect tampering of deployed packages
- Security Measures for Signed models and code
LLM06: Sensitive Information Disclosure
Inadvertent disclosure of sensitive information, proprietary algorithms, or confidential data, leading to unauthorized access, IP theft, and privacy breaches. It is important for consumers of LLM applications to be aware of how to safely interact with LLMs and identify the risks associated with unintentionally inputting sensitive data that may be subsequently returned by the LLM in output elsewhere.
Some common examples of this vulnerability are incomplete or improper filtering of sensitive information in the LLM’s responses, overfitting of sensitive data in the LLM’s training process and intended disclosure of confidential information due to LLM misinterpretation, lack of data scrubbing methods or errors.
To mitigate these risks, LLM apps should perform adequate data sanitization to prevent user data poisoning training model data. Have a robust input validation and sanitization methods to identify and filter out malicious inputs. Apply strict access control methods to external data sources and a rigorous approach to maintaining a secure supply chain. LLM application owners should also have appropriate Terms of Use policies available to make consumers aware of how their data is processed and the ability to opt out of having their data included in the training model.
LLM07: Insecure Plugin Design
LLM plugins are called automatically by the model during user interactions and the application may have no control over the execution. If plugins do not implement sanitization and/or type-checking from the input model, a malicious attacker can construct a malicious request to the plugin, which could result in a system compromise like remote code execution. Further, chain of plugins with inadequate access control can enable malicious inputs to have harmful consequences ranging from data exfiltration, remote code execution, and privilege escalation.
A typical example is a plugin accepting all parameters in a single text field instead of distinct input parameters. Another example is a plugin accepting configuration strings instead of parameters that can override entire configuration settings.
The following are some of the ways help to mitigate plugin vulnerability of LLMs.
- Parameter control by type check and validation on inputs
- Applying OWASP ASVS (Application Security Verification Standard) recommendations to ensure adequate sanitization of inputs. and the following principle of least-privilege which exposes as little functionality as possible while still performing its desired function
- Thorough Testing: Inspect and test with SAST, DAST, IAST for adequate input validation
- Use of OAuth2 and API Keys for effective authorization and access control
LLM08: Excessive Agency
Excessive Agency in LLM-based systems is a vulnerability caused by over-functionality, excessive permissions, or too much autonomy given to “LLM agent”. This enables damaging actions to be performed in response to unexpected outputs from an LLM. Further, this can lead to a broad range of impacts across the confidentiality, integrity and availability spectrum, depending on which systems an LLM-based app is able to interact with.
Suppose a plugin may have been trialed during a development phase and dropped in favor of a better alternative, but the original plugin remains available to the LLM agent. In this case, LLM system is vulnerable to excessive agency.
To prevent this, developers need to perform the following:
- Limit plugin/tools and function scope – Limit the functions that are implemented in LLM plugins/tools to the minimum necessary
- Avoid open-ended functions where possible and use plugins/tools with more granular functionality.
- Limit LLM plugins/tools permissions granted to other systems to the minimum necessary in order to limit the scope of undesirable actions.
- Ensure actions taken on behalf of a user executed on downstream systems in the context of that specific user, and with the minimum privileges necessary.
- Human-in-the-Loop for monitoring and approving impactful actions
LLM09: Overreliance
LLMs can hallucinate producing erroneous factually incorrect inappropriate information in an authoritative manner. This overreliance on LLMs output without confirmation can lead to security breach, misinformation, miscommunication, legal issues, and reputational damage. In a similar manner, LLM-generated source code can introduce unnoticed security vulnerabilities. This poses a significant risk to the operational safety and security of applications.
To mitigate this vulnerability, it is necessary to regularly monitor and review the LLM outputs. Use of consistency tests among various responses is necessary to filter out odd ones. Cross-check the LLM output with trusted external sources. To ensure the information’s accuracy and reliability. Further implement fine-tuning and embedding to improve output quality with less hallucination.
A clear communication of the risks and limitations associated with using LLMs to end users will prepare for potential issues and help them make informed decisions. Another way is to provide APIs and user interfaces that encourage responsible and safe use of LLMs.
LLM10: Model Theft
This vulnerability is concerned with unauthorized access and exfiltration of LLM models by malicious actors. This can occur when LLM models are compromised, physically stolen, copied or weights and parameters are extracted to create a functional equivalent. The impact of LLM model theft can include reputation damage, financial liabilities and losing competitive edge.
If an attacker breaks into a company’s infrastructure, he can gain unauthorized access to LLM model repository leading to model theft vulnerability. Alternatively, a disgruntled insider can leak details of LLM model details. An attacker can query the model API using carefully crafted inputs and prompt injection techniques to collect a sufficient number of outputs to create a shadow model.
Robust security framework consisting of access controls, encryption and continuous monitoring is crucial to mitigating the risks of model theft vulnerability. Restrict the LLM’s access to network resources, internal services, and APIs. It is important to regularly monitor and audit access logs and activities to detect and respond to any suspicious or unauthorized behavior promptly.
SecPod Strategy to handle Top 10 LLM Vulnerabilities
It can be seen that a preventive mechanism is applicable to cover more than one Top 10 LLM vulnerabilities. We think the first and foremost approach is to provide guard railing for both LLM outputs and inputs. This approach filters out undesirable prompt injections being passed as inputs to LLM or filter out buggy generated code or avoid profanity in LLM’s output. Furthermore, this will plug all loopholes to system compromise and remote code execution. In addition, a meticulous scrutiny of access control and authorization will be done to strengthen the protection. The above preventive mechanism will cover prompt injection, insecure output, denial-of-service, sensitive disclosure, overreliance and excessive agency of OWASP Top 10 categories.
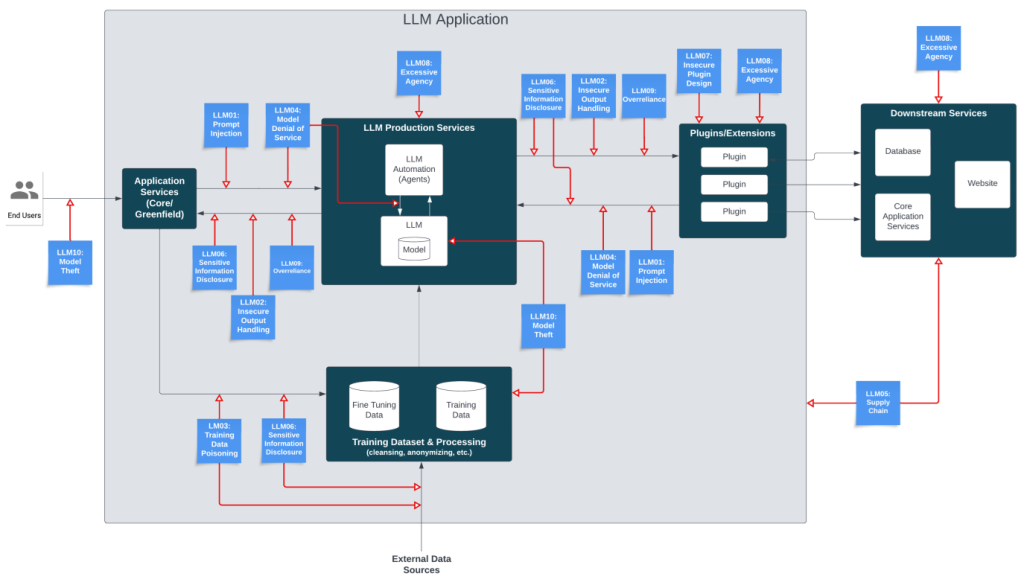
Another important defense is to ensure model integrity and to safeguard LLM ecosystem libraries. The model card for well-known LLMs will be used for checking correct LLMs are in place. An extensive security intelligence collected LLM ecosystem will be used to identity vulnerable libraries. This will also extend to detect vulnerability for plugin libraries followed by strict authentication and authorization checks. This ensures coverage of the remaining data poisoning, supply chain vulnerability, insecure plugin and model theft of OWASP Top 10 vulnerabilities.
To further strengthen the above mechanism, a continuous monitoring of LLM operation and usage will be done. This will help detect and stop abnormal usurp of LLM resources and thus limiting denial-of-service attack. An user-friendly intuitive dashboard will be provided for visualization and quick response.



