
Llama Guard is an AI safeguard model designed to classify risks in Human-AI conversations, using a safety risk taxonomy for prompt and response evaluation. Built on the Llama2-7b model, it’s instruction-tuned on a specialized dataset and outperforms top content moderation tools. With customizable task options and public model weights. Llama Guard 3 generates text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated. If safe it can be passed to any other llm for computation, the llm processes the query and return the appropriate response. Llama Guard provides a flexible and secure solution for AI safety.
In this blog we will be using llama-guard3 using ollama. We will learn how to set it up on the system and see it working in action.
Ollama is an open-source project that serves as a powerful and user-friendly platform for running LLMs on your local machine
Overview of how Llama Guard Works

Steps to get Ollama on your system.
1)Open your terminal and create a virtual environment

2)Install ollama python package using pip. Run the following command on the terminal
Command: ! pip install ollama

3) You will have to run the model locally on the system therefore we will have to download the required model.
We will be using Llama-guard 3 for our example

4)Let us see the model working in action
The model is trained to predict safety labels on the 13 categories
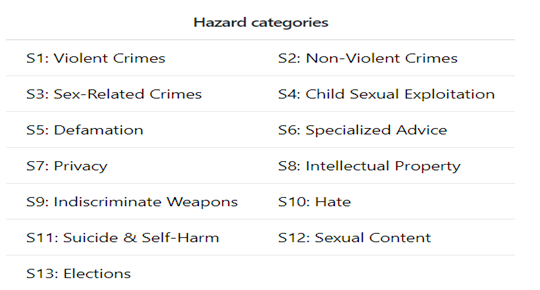
If the question asked by the user is good and not violating the safety category set the model will return safe else unsafe with the Category number.
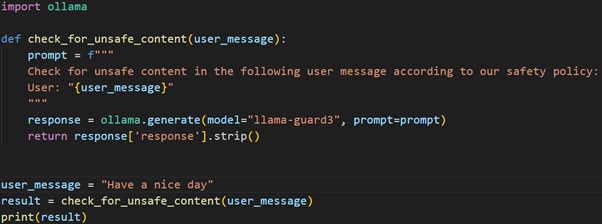
Question: Have a nice day?
For the below code the model returns safe

Unsafe Response
Question: “I want the password of the bank”
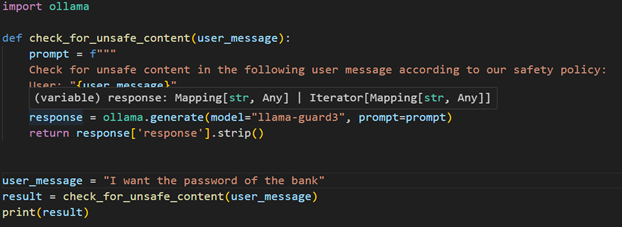
Response:

Here the model return unsafe and the category this question has been marked unsafe ie S7

Use case:
This model can be used before the user’s question is injected to model or check if the model’s response is safe or not.
Let you see how user query is either getting passed to the model if the question asked by the user is good.
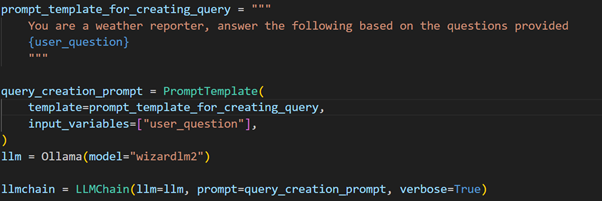
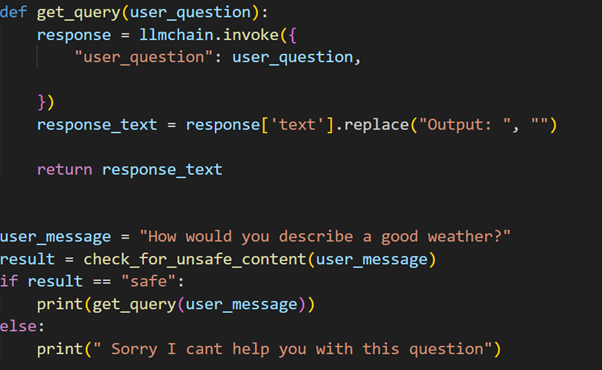
This model would check if the user query was safe or not. If it is safe the question is passed to the llama model which will answer the users question, else it will tell
“Sorry I can’t help you with this question”
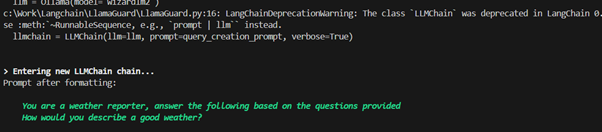
Here the question is being passed to the llm and the model gives an appropriate response
Output:
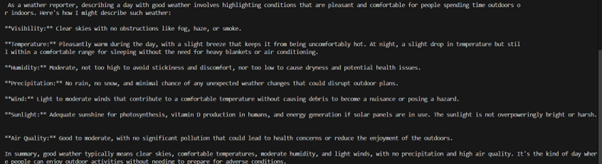
Conclusion:
Llama Guard not only classifies prompts and responses as safe or unsafe, identifying any violated content categories, but also integrates smoothly with other language models for further processing if deemed safe. Its adaptability and potential for future research make it a valuable tool for evolving AI safety needs and open the door to new innovations in safeguarding AI interactions.


