
Recent breakthroughs in AI and large language models (LLMs) have attracted significant attention lately. LLMs excel at rapidly mimicking human-like reasoning by processing vast amounts of corporate data, which has fueled a surge in AI-powered enterprise solutions. The advancement of cutting-edge LLM technology draws from a wide range of fields, including biology, information theory, signal processing, linguistics, and computer science. An exposition of the evolution of LLMs starting from the foundational concept of the simple perceptron to LLM offers valuable insights into their development. It will be useful to have NLP use case perspective for more focus.
We begin with a brief overview of natural language processing (NLP) use cases to understand diverse applications. Following this, we will explore the key stages in NLP’s evolution, starting from the 1950s to the present. We’ll first delve into the rule-based approaches that dominated early NLP applications. Then we trace the revival of neural networks, highlighting major breakthroughs along the way. This includes the development of both statistical methods and deep learning techniques. Finally, we will examine the transformer architecture and other innovations that paved the way for various types of large language models (LLMs).
NLP and its Applications
NLP, a sub-field of AI, enables machines to understand, interpret, and generate human language in a way that is both meaningful and useful. Natural Language Understanding (NLU) and Natural Language Generation (NLG) are two important sub-branches of NLP with some intersection between them. NLP uses computational linguistics, which is the study of how language works, and various models based on statistics, machine learning, and deep learning. NLG deals with how to generate coherent and contextually relevant text emulating humans like writing stories and poetry. NLU is concerned with interpreting human language, extracting meaning, intent and context and taking appropriate actions.
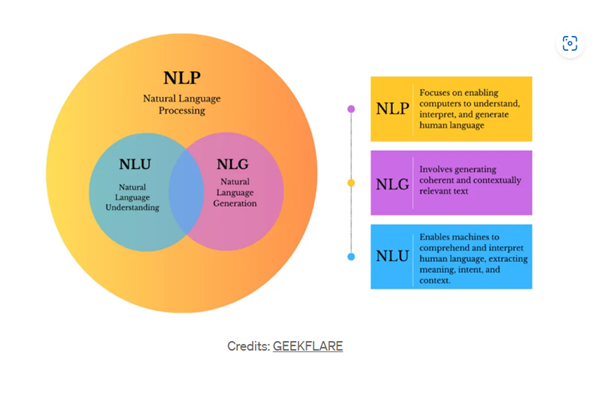
An important use case of NLP is sentiment analysis, where the objective is to determine the emotional tone of text – positive, negative, or neutral. A recent addition is also to decide whether the content is toxic or not. The other NLP use case is to detect spam emails and segregate them. The use case of automatic machine translation of one language to another is well-known. It will be useful to pick up key words and extract applicable information for downstream applications. This feature will come in handy for smart assistant, document analysis and social media applications. Yet another use case is to perform abstractive and extractive summarization. Another popular application is chatbots which can simulate human-like conversation with prediction and summarization capabilities.
A Brief History of NLP
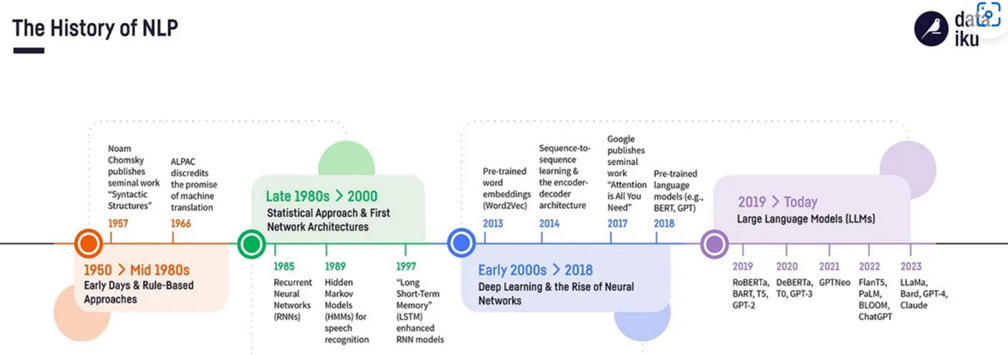
NLP’s origins trace back to the 1950s that were born during World War II. The neural network is then at the nascent stage of development and simple mathematical models of neurons and perceptron based on biology are proposed. An important highlight of NLP usage is public demonstration of automatic translation of over 60 Russian sentences into English (IBM and Georgetown University) in 1954. A significant development in 1957 is publishing a highly influential “Syntactic Structures” by Noam Chomsky. He introduced concepts of transformational grammar, profoundly influencing computational linguistics. In 1960 MIT demonstrated SHRDLU which worked with “blocks” in in a restricted vocabulary framework. In 1964 ELIZA, a forerunner of moder-day chatbot, provided a surprisingly human-like interaction. This one is capable of coping with the famous Turing test that is designed to distinguish humans from computers. In between 1960-1970 many conceptual systems were developed and by the 1980s, most NLP were based on complex handwritten rules. From 1980 onwards NLP progress is driven by developments in neural networks
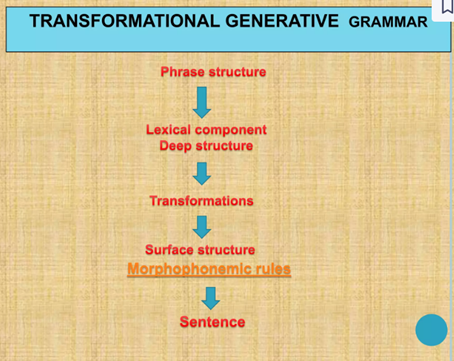
Chomsky’s thought that language acquisition is innate and noted similar features of languages like nouns, verbs etc. He proposed transformational grammar which aims to capture the generative nature of language. He highlighted as to how a finite set of grammar rules can produce an infinite number of sentences. The language is organized in a hierarchical fashion, with smaller units combining to form larger ones and has a recursive ability to embed phrases or clauses within each other, creating an infinite nested structure. Moreover, generative grammar posits that language use is creative and flexible, rather than simply a system of rule-governed behavior. Chomsky thought language can be considered to deep structure, surface structure and transformation rules to convert deep structures to surface structures. The surface structure is the actual spoken or written form of the sentence, which results from transformations applied to the deep structure. Transformation rules account for various syntactic phenomena, such as the formation of questions, passive constructions, and other sentence variations. For example, a transformational rule might convert a declarative sentence like “The cat is on the mat” into a question like “Is the cat on the mat?”
Chomsky’ seminal work has shaped how language structure was understood and provided a formal way to model syntax. While his work was more theoretical, its implications on NLP are significant. Chomsky’s hierarchical approach to language, later formalized as the Chomsky hierarchy, categorized languages into different types based on their grammar complexity (e.g., regular, context-free, context-sensitive). This helped linguists and computer scientists develop algorithms that could process language at various levels of complexity. His formalism provided the foundation for rule-based approaches in early NLP, where systems attempted to generate and parse sentences based on syntactic rules. Another impact of Chomsky is on the development of rule-based NLP systems. The focus was on creating systems that could follow a set of syntactic rules to parse and generate human language. These systems attempted to capture the deep structure of sentences and transform them into surface structures, aiming to reflect how humans process language syntactically. Chomsky’s work influenced early parsing algorithms, which sought to replicate these grammatical transformations computationally. Chomsky’s work inspired formal linguistic theories that impacted computational linguistics, especially in understanding what kinds of syntactic structures were computationally feasible. His distinctions between different classes of languages and grammar helped define the boundaries of what algorithms could achieve.
Between 1970 and 1980, natural language processing (NLP) experienced significant development, particularly in moving from purely theoretical models towards more practical applications. This period saw the rise of symbolic approaches, development of early parsing techniques, and growing interest in semantic understanding, laying the groundwork for the statistical and machine learning advancements that would follow in later decades. Symbolic and rule-based system approaches are focused on encoding syntactic and semantic rules manually, attempting to model language through sets of logical rules derived from human expertise. Inspired by Chomsky’s ideas, CFG parsers were developed. Another interesting development of this period was the rise of artificial intelligence and expert systems, which aimed to mimic human reasoning. Knowledge representation was a key focus in NLP, as researchers sought to encode real-world knowledge that could be used by machines to understand and generate natural language. Notable progress is made in the area of machine translation which gained more practical traction in the 1970s. Rule-based approaches were prominent, as researchers worked on mapping grammatical structures between languages using hand-crafted linguistic rules. SYSTRAN, was developed during this time and applied rule-based methods to automate translation between different languages. SYSTRAN was notably used by the U.S. Air Force for translating Russian documents during the Cold War.
A major challenge of rule-based systems in this era was their inability to handle the inherent ambiguity of natural language. Hand-crafted rules often failed to account for all possible variations in how language is used, making it difficult to scale these systems for broader, more diverse applications.The lack of computational power limited the complexity and scale of NLP systems, which restricted the scope of their applications to constrained environments or specific domains.
Neural Networks Evolution from 1940s-Present
The evolution of neural networks from their early inception in the 1940s to the present day is a fascinating journey that mirrors the broader advancements in artificial intelligence and computational techniques. The field has gone through periods of rapid development, stagnation, and resurgence, driven by improvements in theory, computational power, and data availability.
Neural networkshave roots in both biology and computer science, drawing inspiration from the structure and functioning of the human brain. In 1943, Warren McCulloch and Walter Pitts introduced the first mathematical model of a neuron in 1943, which showed that neurons could be represented as binary threshold units capable of performing logical operations (like AND, OR, NOT). Therefore, the established networks of artificial neurons could, in principle, compute any mathematical function, laying the foundation for neural networks as a computational paradigm. In 1949. Donald Henn suggested that neural connections strengthen when neurons are active together. This provided the basis for the first learning rule of artificial neurons. In 1958, Frank Rosenblatt developed perceptron, a type of neural network based on McCulloch-Pitts neurons. It was a simple linear classifier that could recognize patterns. He also showed how perceptron learning algorithm enabled the system to adjust its weights based on input-output pairs, effectively “learning” from data. In 1969, Minsky and Papert, in their book, “Perceptrons” demonstrated the limitations of the perceptron to classify non-linear data which led to AI winter till middle 1980s. They showed that a single layer perceptron cannot solve XOR problem which led to temporary decline in neural network research.
The resurgence in neural network started from Hopfield (1982), who proposed a type of recurrent neural network (RNN) which functions as a content-addressable memory system. This allowed patterns to be stored and retrieved based on input clues. In 1986, Rumelhart et.al developed a backpropagation algorithm that allowed multi-layer perceptron (MLP) to be trained efficiently. They showed how MLP addressed XOR problem overcoming earlier limitations thus achieving a significant breakthrough. The universal approximation theorem for NN, which states that a neural network with one hidden layer can approximate continuous functions on compact sets with any desired played a crucial theoretical role. This revived interest in neural networks, and the 1980-1990s saw the emergence of more complex neural architectures.
In the early 1990s, RNNs were developed to handle sequential data. They maintained a hidden state that could capture temporal dependencies between data points, which made them effective for processing time series and language data. Yann LeCun introduced convolutional neural networks (CNN) in the late 1980s and further refined them in the 1990s, CNNs were designed to mimic the visual processing system of the brain. They became especially effective in image recognition tasks due to their ability to capture spatial hierarchies in data. RNN struggled with challenges like vanishing/exploding gradients, insufficient computational power, and limited labeled data. Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) were proposed improvements to mitigate RNN’s limitations to some extent.
The 2010s saw an explosion in interest and success in deep neural networks, largely driven by the availability of large datasets (e.g., ImageNet), powerful GPUs, and advances in algorithms. In 2012, Alex Net, a deep CNN, designed by Alex Krizhevsky et.al popularized deep learning and CNNs for computer vision tasks. Further deeper CNNs, like VGGNet and ResNet, further improved image recognition, using techniques like residual connections to solve the vanishing gradient problem. In 2014, Ian Goodfellow introduced a new class of Generative Adversarial Networks (GAN) where two networks (a generator and a discriminator) compete with each other to generate realistic data. GANs opened up new possibilities in unsupervised learning and creative applications (e.g., image synthesis). In 2017, Google team of researchers introduced the new concept of transformer model, which revolutionized NLP. They eliminated the need for recurrent architectures (like RNNs) and instead used attention mechanisms to process input data in parallel, allowing for greater scalability. They further lead to foundational LLM models like Bidirectional Encoder Representations from Transformers (BERT) and Generative Pretrained Transformer (GPT) with spectacular success in generating human-like text and understanding. They have pushed the boundaries of neural networks in terms of their applications in text generation, translation, summarization, and more. Currently, there is ongoing research to further integrate insights from neuroscience into neural networks to make them more efficient, interpretable, and generalizable. Concepts like spiking neural networks and neuromorphic computing are examples of this.
Statistical Approach to NLP – 1980-2000
Chomsky criticized a probabilistic approach and promoted rule-based understanding. However, as NLP progressed, rule-based systems could not handle the variability and ambiguity of natural language. Hence, the field gradually shifted towards statistical and machine learning methods. Despite this shift, Chomsky’s influence remained, as many modern NLP models still incorporate syntactic structures, albeit in a more flexible and data-driven way, using techniques like dependency parsing or syntax-aware embeddings. Computational linguistics means applying the theory of grammar or the theory of lexical semantics to analyze and understand language data. These theories provide a framework for understanding the structure and meaning of language, which can be used to develop more accurate and efficient NLP models.
The statistical approach involves using probability models, feature extraction, model selection, multivariate analysis, time series analysis, computational linguistics, ML to interpret and generate human-like language. Unlike earlier approach statistical methods need a large corpus of text to infer patterns, associations, and structures.
Probabilistic models estimate the likelihood of words based on their frequency in large datasets. Use of ML algorithms, such as Naive Bayes, Hidden Markov Models (HMM), Conditional Random Fields (CRF) and neural networks to capture uncertainty and ambiguity of NLP data. Large, annotated datasets are essential for training the models. Statistical NLP often involves extracting relevant features from the input data, such as n-grams, grammatical features, or syntactic dependencies. These features can be used as inputs to statistical models or machine learning algorithms for tasks like language modeling, text classification, or machine translation. Statistical NLP often involves selecting and evaluating different models for a given task, using techniques like cross-validation or BIC (Bayesian Information Criterion). This allows for the evaluation of the performance of different models and the selection of the most appropriate one for a given dataset. Multivariate analysis uses principal component analysis (PCA) to identify patterns or relationships between different linguistic features
Neural Networks with Statistical Models
Traditional linguistic statistical models used n-grams, which a sequence of a specified number of adjacent symbols in a language dataset and term Frequency–inverse document frequency (tf-idf), a statistical technique that measures how important a word is to a document in a collection of documents. They are often used with Hidden Markov Models (HMM) and rely onconditional probabilities to estimate the likelihood of a word given the previous words, but they struggle with long-term dependencies due to the Markov assumption (that the current state depends only on the previous state).
NN introduced a new way of word embeddings, such as Word2Vec, GloVe, and FastText. These are dense, low-dimensional vector representations of words to capture semantic and syntactic relationships. In Word2Vec, NNs generate embeddings by optimizing a model to predict nearby words in a text. Deep learning models can also take advantage of pre-trained word embeddings, which are learned using statistical methods and enhance performance in text classification tasks. For example, in a sentiment analysis, a neural network model is trained to classify a movie review as positive or negative by maximizing the probability of the correct label based on learned patterns from the data. NNs predict word sequences based on learned probability distributions, similar to statistical n-gram models but with greater capacity for handling context and complexity. Thus NNs overcome the limitations of early statistical approaches by better handling non-linear relationships, long-range dependencies, and richer feature representations. By integrating deep learning techniques with statistical principles, NNs provide a more robust and accurate way to handle the complexity of natural language, allowing for significant advancements in NLP tasks. Neural networks often optimize statistical loss functions (e.g., cross-entropy) during training. Even state-of-art transformers (like BERT, GPT, and T5) use a self-attention mechanism to weigh the importance of words in a sentence and statistical masked language modeling (BERT) or AR modeling in GPT are used for optimization.
Hidden Markovian Models (HMM)
HMM consists of hidden states, which are un-observable (e.g., parts of speech, like noun or verb), the observable outputs, transition probabilities and emission probabilities. Transitional probabilities model the likelihood of a word (or state) based on preceding words (or states). Ex:- P(si∣si−1) (Bigram); P(si∣si−1,si−2) (3-gram). Emission Probabilities can be used to model the likelihood of observing a word given the current hidden state. If POS tagging is followed, the prob is observing “run” given “verb” state is P(wordi=run∣POSi=verb). Viterbi algorithm is used to find the best sequence that maximizes the joint probability of states and observations
While this can be sufficient for some tasks, they often struggle to capture more complex patterns in data, such as non-linear interactions or long-range dependencies. HMMs have limited modeling and scaling capabilities with limited flexibility. Hence, they have been replaced by better modern techniques. Modern NLP techniques such as Recurrent Neural Networks (RNNs) and Transformers can model much more complex relationships between observations and hidden states.
RNN and CNN Development Milestones
Ronald J. Williams et. al developed the real-time recurrent learning algorithm. This algorithm was designed to train RNNs using a variant of backpropagation algorithm through time, In 1990-2000 David E. Goldberg et. al developed the first LSTM network, which introduced the concept of a cell state and gates to control the flow of information into and out of the cell state. GRU is a further improvement of LSTM network.In the 2000s, researchers like Yoshua Bengio and his colleagues developed the concept of bidirectional RNNs, which process input sequences in both forward and backward directions. This allows bidirectional RNNs to capture both past and future context, leading to improved performance on tasks like language modeling and machine translation.
Hubel and Wiesel (1962) conducted studies on the visual cortex of cats and discovered the concept of receptive fields. They found that certain neurons in the brain responded to specific regions of the visual field, which laid the foundation for the idea of localized processing in CNNs. Kunihiko Fukushima (1980) introduced Neocognitron to use a hierarchical, multilayered architecture for pattern recognition tasks. It introduced the concepts of convolutional layers and pooling layers, which allowed the network to learn features hierarchically. Yann LeCun et al. (1998) developed LeNet-5 architecture the first true CNN designed for practical applications. LeNet-5 incorporated convolutional layers, pooling layers, and fully connected layers, all trained using backpropagation and gradient descent.
Deep Neural Networks Developments
The term “deep” refers to multiple layers of neurons (or nodes) in the network. This allows learning hierarchical representations of data, where each successive layer learns increasingly abstract and complex features. For example, the early layers in a deep CNN may detect edges or textures, middle layers may detect patterns like eyes or ears, and deeper layers may recognize whole objects like a cat or dog. Deep learning automatically learns features from raw data through training, without the need for manual feature extraction. In contrast, shallow networks are often insufficient for complex tasks. They need an exponentially larger number of neurons to represent complex functions, poor in generalizing to unseen data and prone to overfitting.
Here are milestone developments regarding deeper RNN. Hochreiter et al. introduced LSTMs in 2014 to address the vanishing/exploding gradient problem. They use memory cells and gates to control the flow of information, enabling them to learn complex patterns in data. Cho et al. came up with Gated Recurrent Units (GRU) as a simpler alternative to LSTMs, with fewer parameters and computation requirements. They are as effective as LSTM in many NLP applications. Bahdanau et al. in 2015, attention mechanisms allow RNNs to focus on specific parts of the input sequence when processing it. This is particularly useful for tasks like machine translation. Vinyals et al. in 2015 extension to multi-head attention allowed RNNs to capture complex contextual relationships in input sequences. Combining multiple RNN models in an ensemble manner is the latest trend particularly, for NLP tasks. By combining the strengths of different models, ensembles can often outperform any single model, especially when dealing with complex input data.
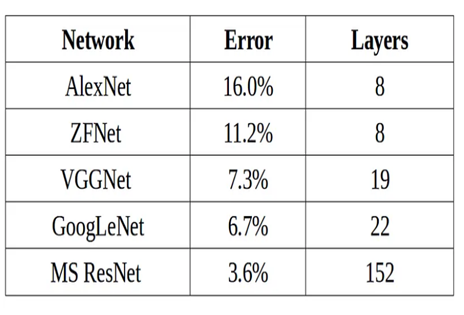
Here are significant advancements regarding deeper CNN. The AlexNet architecture in 2012 used 8 layers and 64 nodes per layer to achieve state-of-the-art performance on the ImageNet dataset. VGG (Visual Geometry Group) at Oxford (2014) used very small convolutional filters (3×3) but stacked a large number of convolutional layers (up to 19 layers in VGG-19) to get better performance. GoogLeNet (2014) used Inception module architecture and 22 layers for a more efficient model with fewer parameters compared to VGG. ResNet (Residual Networks, 2015) introduced the concept of skip connections and with 152 layers improve performance without the risk of overfitting or degradation. The performance of these CNN networks are shown below:
Transformer Architecture and LLMs
While transformers and large language models (LLMs) do not explicitly rely on Chomskyan grammar, the foundation laid by his syntactic theories still resonates in the way NLP models think about structure. For instance, NLP models often capture syntactic relationships indirectly through training on large datasets, even if they don’t explicitly use grammar rules.
The development of the Transformer architecture (introduced by Vaswani et al. in the 2017 paper “Attention is All You Need”) was a landmark event in the evolution oflarge language models (LLMs). It addressed many of the limitations of previous neural architectures like recurrent neural networks (RNNs) and convolutional neural networks (CNNs), setting the foundation for the rapid advancement of models like BERT, GPT-3, GPT-4, and other cutting-edge LLMs.
Despite the advances made in RNNs and LSTMs, they suffered from a fundamental limitation of processing data sequentially, step by step, and hence making it hard to parallelize and scale. Transformers replaced recurrence with a self-attention mechanism, allowing models to process entire sequences simultaneously, enabling parallelization during training. This dramatically improved training speed and allowed much larger datasets and models to be trained efficiently, key factors in the evolution of modern LLMs.
The self-attention mechanism allows the transformer to model relationships between any two words in a sentence, regardless of their distance from each other. Transformers could focus on both nearby and distant words equally well. This makes it especially effective for capturing the nuances of language where context from earlier parts of a sentence might be essential to understanding later parts. Self-attention allows each word to be influenced by all other words in a sentence, giving the model a richer and more contextualized understanding of language. This ability to dynamically “attend” to relevant information is crucial for the nuanced understanding of complex language tasks that LLMs handle, like text generation, summarization, and translation. This versatility allows it to excel at a wide range of NLP tasks like language translation, summarization, sentiment analysis, and even code generation with minimal adjustments. The flexibility of the architecture allows for multitasking, which has become a significant feature in large-scale models like GPT-4. Further, the autoregressive nature of GPT-like models allows for open-ended text generation, which is one of the most exciting applications of LLMs today. These models can generate human-like text, making them useful for creative applications like writing stories, generating poetry, and even producing code.
The Transformer architecture has been instrumental in the evolution of LLMs, acting as the backbone for nearly all state-of-the-art models in natural language processing today. Its ability to handle long-range dependencies, scalability, efficiency through parallelization, and self-attention mechanisms enabled the creation of massive models like GPT-3, BERT, and beyond. These advances have fundamentally changed how we interact with machines, enabling unprecedented progress in understanding and generating natural language.
Conclusion
We have shown a glimpse of LLM evolution within the realm of NLP from foundational rule-based system to modern transformer-based architecture.
Initially, NLP relied heavily on rule-based methods, shaped by theories like Noam Chomsky’s transformational grammar, which emphasized the generative and recursive nature of language. Neural networks architecture inspired by biology evolved from perceptron, capable of basic pattern recognition. The NN architecture aided by insights from computational linguistics replaced cumbersome rule-based system for NLP. The statistical approaches of the 1980s to 2000s, including probabilistic models and word embeddings like Word2Vec, laid the groundwork for integrating neural networks with statistical principles. These improved NN architectures enabled more robust modeling of language, addressing limitations of earlier rule-based and statistical methods, and pushing the boundaries of NLP and LLM development.
These latter statistical models, machine learning techniques, and neural networks better handled the inherent variability and ambiguity of language. By the 1980s, neural networks gained prominence, and notable advancements included the development of Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and later, transformers.
Transformers, introduced in 2017, eliminated the need for recurrent structures and leveraged attention mechanisms for parallel processing, significantly improving scalability and performance. This innovation led to the development of foundational models like BERT and GPT, revolutionizing NLP tasks such as text generation, translation, and summarization.
In conclusion, the evolution of LLMs has been driven by advances in both theory and computation, from early rule-based systems to the transformative power of neural networks and transformers, making significant strides in tasks like language understanding, text generation, and machine translation.


