
Ever tried reading a novel in one go? Neither have I! Just like our brains can only handle so much at once, Large Language Models (LLMs) like GPT-4 have limits on how much text they can process in one shot.
If you are trying to pass a lengthy content for a large language model to train, you just can’t pass it as it is. You need a strategy. Thats where text splitters steps in. Recursive character text splitter proves to be the recommended and the best one.
What does recursive character text splitter do?
It tries to split on them in order until the chunks are small enough. The default list is [“\n\n”, “\n”, ” “, “”]. But what does this actually mean?
| “\n\n”: This means splitting by Paragraphs Paragraph This is the first paragraph. This is the second paragraph. Chunks Chunk1: This is the first paragraph Chunk2: This is the second paragraph “\n”: This means splitting by Sentences Sentence This is the first paragraph. This is the second paragraph. Chunks Chunk1: This is the first paragraph Chunk2: This is the second paragraph |
| “ ” : This means splitting by words Sentence This is the first paragraph. Chunks Chunk1: This Chunk2: is Chunk3: the Chunk4: first Chunk5: paragraph |
| “” : This means splitting by character Word Hello Chunks Chunk1: H Chunk2: E Chunk3: L Chunk4: L Chunk5: O |
Let’s see how the Recursive Character Text Splitter operates in action with a sample text.

Let’s apply the Recursive Character Text Splitter to it:
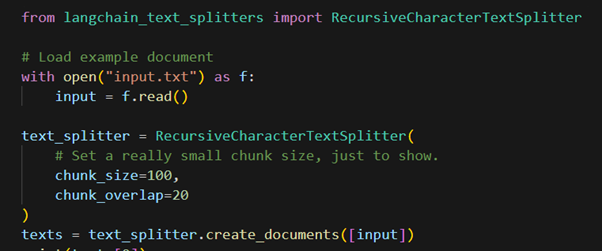
Lets breakdown the code:
- The code reads the input file
- Applies recursive character text splitter on the contents
- The chunks are stored in separate document and returned
Within the recursive character text splitter we see two parameter , lets see what are they?
Chunk Size: LLMs have a limit on how much text they can process at once. By controlling the chunk size, you ensure that each piece of text stays within the model’s token limit. This allows you to process large documents in smaller, manageable segments without overwhelming the model.
Chunk Overlap: When you split a document into chunks, some important context might get cut off between chunks. Overlap ensures that the last part of one chunk is included in the next chunk, maintaining continuity and context, which leads to more coherent outputs from the model.
Output Example

The first split focuses on paragraph titles, followed by a sentence split that respects the chunk size of 100. The third chunk retains 20 characters from the previous chunk, continuing with the next set of sentences.
Conclusion
In conclusion, the Recursive Character Text Splitter isn’t just a handy tool—it’s a behind-the-scenes hero when it comes to optimizing large language models. By breaking down documents into manageable, meaningful chunks, it ensures that even the most complex texts are processed smoothly. Whether it’s crafting the perfect response or diving deep into your data, this clever technique keeps everything running efficiently. So next time you chat with an AI, remember—somewhere, text is being split just right, keeping your conversation flowing!


